

The Everything Database
How LLMs became the ultimate database
Imagine you're building an app and suddenly realize you need to map (potentially thousands of) food dishes to their countries of origin. Or you need cities matched to time zones. Or authors to book genres. A few years ago, every single app would need its own custom tables.
Or imagine you’re an analyst pulling rows and rows of data from multiple database tables or using VLOOKUPs to connect multiple Excel files. You realize you need to create several reference tables, such as geographic information or business profile details. A few years ago, you’d need to create reference tables for each connection.
Both of these scenarios would require hours of tedious data sourcing and scrubbing.
But what if there were already a table out there that knew everything? One that understands "Margherita pizza is Italian," "Athens is in Greece," and "Michael Jordan played basketball and baseball."
Turns out there is. Large Language Models (LLMs) are basically the ultimate lookup table that someone else already built and maintains for you.
VLOOKUP Without the Tables
Instead of building and maintaining reference tables for every specific use case (which takes a lot of time), you're essentially running database joins (or VLOOKUP in Excel terms) against the LLM's knowledge. Think of it as having access to (almost) every reference table you'd ever need, without building any of them.
This framework has fundamentally changed the way I think about using LLMs, especially when developing new solutions and tools.
What Makes This So Powerful
While a lot of the discussion around LLMs focuses on how these models predict text, pre-trained LLMs have basically absorbed and organized the relationships between everything. Of course, we exaggerate when we say ‘everything’, but you get the idea. LLMs know a lot about a lot.
Enter the Everything Database
I often write complex database queries in order to join multiple tables together. Now, a lot of it could potentially be replaced with an LLM and plain English:
Instead of writing SQL code against your own reference databases like:
SELECT foods.name, cuisines.origin_country, countries.climate
FROM foods
JOIN cuisines ON foods.cuisine_id = cuisines.id
JOIN countries ON cuisines.country_id = countries.id
WHERE foods.name IN ('sushi', 'pasta', 'tacos')You can just prompt an LLM:
"Look at this list: sushi, pasta, tacos.
Tell me where each cuisine originated and what the climate is like there"The LLM connects all those dots instantly, without you having to build the relationships between foods → cuisines → countries → climates. Really powerful, when you think about it.
The Best Part: It Handles Messy Real-World Data
Traditional databases or Excel VLOOKUP can break when you don't have exact text matches or more advanced fuzzy matching. But LLMs can easily work with partial information or ‘close-enough’ matches:
Your user might ask: "That HBO show with dragons and betrayal"
Traditional database: ERROR - a match for 'dragons and betrayal' not found
LLM: "You probably mean Game of Thrones..."
The Everything Database doesn't just store exact matches. It understands synonyms, abbreviations, descriptions, and vague references. It's like having a database that can think like a human. Think of the Everything Database like VLOOKUP or JOIN operations, but against an incredibly comprehensive reference table. Here's how the process actually works:
Example: City → Travel Info Lookup
Traditional Approach: Multiple joined tables
-- You'd need to build and maintain these relationships:
cities_table → countries_table → climate_table → tourism_table
LLM Approach: Single query with multiple columns
# Input data (in practice this would be a longer list or csv file)
cities = ["Barcelona", "Prague", "Lisbon"]# Prompt (replaces complex JOIN)
For each city, return: city, country, best month to visit, reason why
Input = {cities}# Output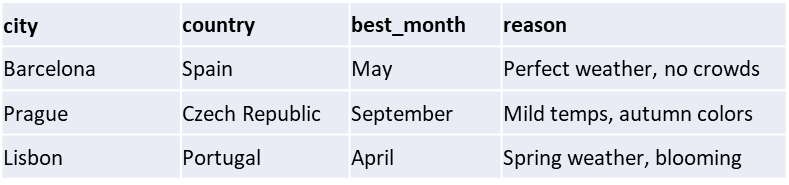
The Hidden Database
LLMs perform these “lookups” so naturally that we don't even realize what's happening. When you ask, "Which 19th century British novel do you recommend for me to read on my vacation?", you're not just getting a predictive chat response - you're effectively executing a query against a massive, implicit database that contains relationships between millions of books, authors, publishers, themes, and literary connections.
This fundamentally transforms how we should think about product and data design, particularly when working with data at scale. Instead of asking, "What tables do I need to build?" we can start asking, incrementally, "What relationships can I query from the Everything Database?" It's a shift from database construction to database extraction.
Now, let's be clear: this doesn't eliminate the need for all database design. You'll still need custom databases for:
Proprietary data (your customer records, transactions, etc.)
Real-time data (current inventory, live pricing, user sessions)
Mission-critical exact lookups (financial records, compliance data)
Highly specific business logic (decision rules, custom calculations)
The Everything Database handles the world's general knowledge. Your custom databases handle your specific business data.
What’s Coming Next
So, the next time you think "I need to build a table for this," try asking: "Could I just query an LLM instead?"
Increasingly, the answer is likely yes. The Everything Database already exists, it's already filled with data, and it's just waiting for you to ask the right questions.
Adventure on.